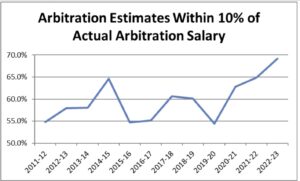
With the last of the arbitration hearings officially in the books, we can now officially report that this was the most accurate year that the MLB Trade Rumors Arbitration Model has ever had. The model estimated salaries within ten percent of salaries for 69% of cases – breaking the previous record of 65% and well above the 54% low point just three years ago.
When I began working on this model way back in 2011, I defined success based on how often my model was within ten percent of the actual arbitration salary for all arbitration-eligible players who signed one-year deals. The initial goal was to be within ten percent for half of such cases. For the 2011-12 arbitration season, the model was within ten percent on 55% of all cases. The model has consistently been in that range or higher, peaking at 65% in the 2014-15 arbitration season, while only dipping below it once with 54% in 2019-20. It averaged 58% over its first nine years.
Over that time, I repeatedly ran tests on the model, considered new modeling techniques, and had discussions with agents and others with experience in the arbitration space about how to improve the model. There were steps forward, although after picking each piece of low-hanging fruit, the gains were smaller. Ultimately, I pivoted to a focus on more accurate and cleaner data. This was initially something that Bryan Grosnick helped with behind the scenes, and Darragh McDonald took over last year. They both helped tremendously.
One important process change that I incorporated into model updates in recent years is checking which players would have been the “biggest misses” after updating the model. In many cases, the salaries that “missed” were not reflective of the actual salaries earned. Yet the model was awkwardly contorting itself to fit those purported outcomes. Some of the process of improving data quality was just a matter of finding typos. But in many cases, it was about correctly identifying the “true” arbitration salary a player received. When players avoid arbitration via settlement, they often get performance bonuses, signing bonuses, options for future years, or multi-year agreements. These cases are incorporated into the modeling process where appropriate, but sometimes the “salary” a player literally earned was not really intended to account for the actual arbitration award he would have gotten at a hearing. Cleaning the data involved some subjectivity, but it was designed to better record the intended salary that teams and agents were treating as a baseline when they negotiated more complicated agreements.
More tedious updates to data accuracy are not the most thrilling part of model building. Coming up with creative mathematical methods or just innovative variables to utilize is a more rewarding intellectual exercise for the researcher. But the truth is that better data is often more important than a slightly smarter model. I will continue to evolve the model based on the relevant statistics and factors utilized in the arbitration process, but in recent years I ultimately improved the model more with better data without structuring it differently.
As a result, the model should be more accurate in future years than it has been in the past. See below for a graph showing the performance of the model each year.